Well, tell you what, you can try it yourself. This is all done with Google ImageFX, which is free to use up to a certain number of generations per day (which I hit frequently, lol). Here's the basic prompt and then I'll post the first four images that come out of the AI generator so you can get an idea of the differences that can pop up.
Prompt:
85mm telephoto DSLR photo high angle view of a smiling woman standing with one hand on her hip and the other waving as she looks up toward the top of the scene. She is an 18-year-old slim buxom Caucasian woman with short blonde hair in a pageboy style and olive skin, no makeup or piercings, wearing a purple glittery sleeveless scoop neck crop top with black trim, a purple collar, a wide purple hip-hugging belt slung low around her hips, black bikini bottoms, black fingerless gloves, fishnet pantyhose that cover all of her legs, and black buckled knee-high boots.
Images:
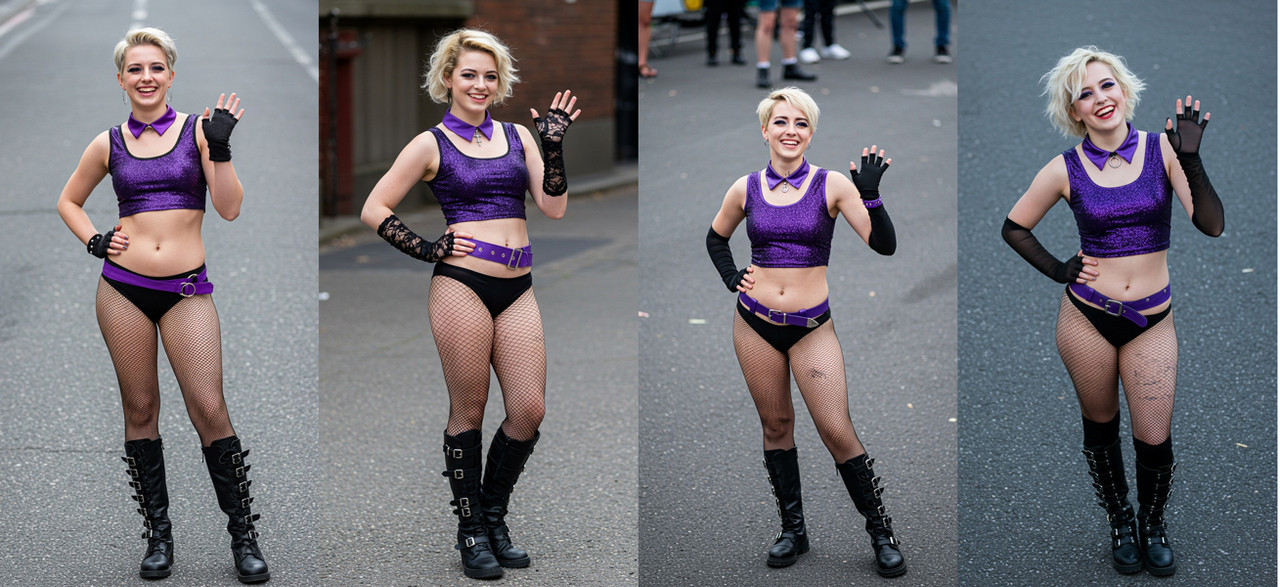
I used some of
MollySmall's suggestions on how to design prompts to get some highly realistic imagery. In this particular image I didn't describe any background info so it just put her wherever it wanted, in this case in a street for some reason, but if you wanted to add background stuff you can put it after the description.
Generally the more detailed you get, the more the AI will try to meet your requests, and if you don't say something then it will do whatever it wants. So if I didn't say slim, she would sometimes come in varying body shapes. I like to say "buxom" but most of the time you can't tell the difference. If you try to get specific like say DD-cup or huge breasts, most of the time the AI just fails to make the image entirely. Google ImageFX won't do nudity or anything it considers anywhere near pornographic, so even something innocuous like "low-cut" will fail, and depending on the pose, sometimes it won't even do fishnets. Notice I had to say "fishnets that cover all her legs" because if I don't they will be more like socks half the time, or be incomplete, or be super sparse that doesn't give me the result I want.
Notice in the four images all the things that are different despite me stating otherwise: the hairstyle, the belt, the boots in the fourth panel (most of the time it's 50-50 whether I get thigh boots when I say knee-highs), etc. So quite often it just does its own thing which can be frustrating. But also notice the differences where I didn't get specific: the cross hanging from her collar, the lacy gloves, the big hoop earrings, the angle on the belt, the flaws in the fishnets, and so on. If those things are a problem, alter the prompt to change them, but just be aware if you get too much information there, the AI will sometimes refuse to make the image at all, especially with highly complex backgrounds. When I do multiple characters, I often have to just be more vague and live with whatever it gives me.
Usually when I go for an image it will have 3 or 4 things that aren't working properly and I refine them with more adjectives or commands, usually related to the pose or shot angle, but even so I often find myself running 10 or more generations just hoping to get that one where everything lands perfectly. It can be frustrating and you need a LOT of patience. I can see why MollySmalls had to spend so much time and effort on this, and it makes me appreciate Maggie & Jane all the more!


























